Agenda
| LLMs: de texto a acciones + como correrlos | + demo 1 |
| MCP: protocolo, JSON-RPC, FastMCP | + demo 2 |
| El proyecto: arquitectura, Scapy, ARP | + demo 3 |
| SYN scan, sniffing, traceroute | |
| Comportamiento emergente | |
| Cierre + Q&A |
Large Language Model
Un LLM es una red neuronal entrenada con enormes cantidades de texto para predecir la siguiente palabra en una secuencia.
- Entrenado con billones de tokens (libros, web, codigo)
- Aprende patrones estadisticos del lenguaje
- No "entiende" — predice probabilidades
- GPT, Claude, Llama, Gemini — todos funcionan asi
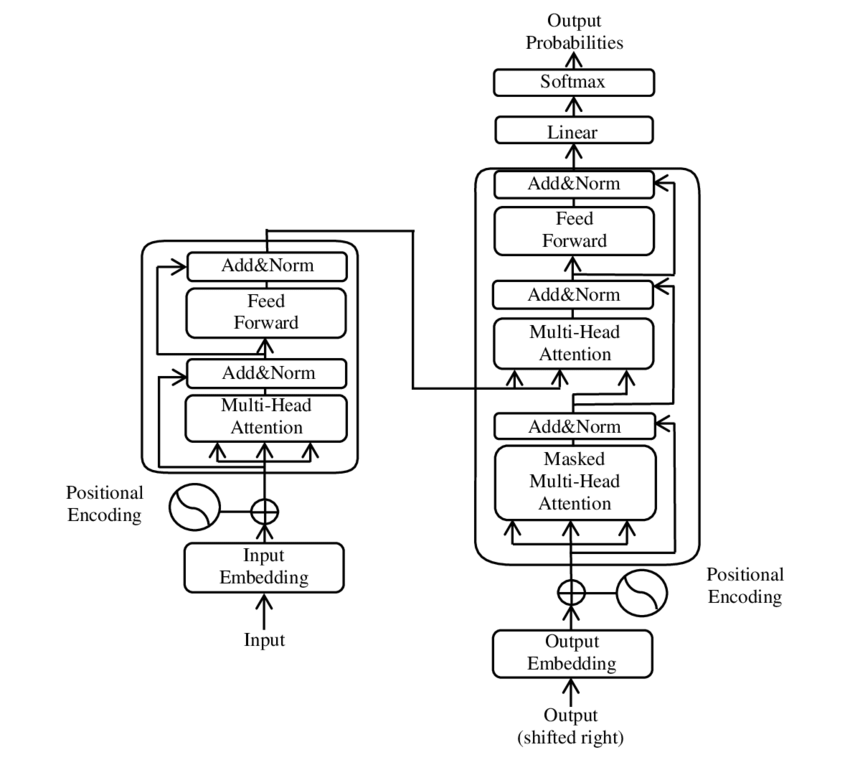
Arquitectura Transformer — Vaswani et al., 2017
Prediccion del siguiente token
Un LLM es autoregresivo: genera un token a la vez, condicionado a los anteriores.
Softmax
Logits → probabilidades. La palabra con mayor probabilidad se elige.
Temperatura
0.1 = determinista • 0.7 = balanceado • 1.5 = creativo
Generacion autoregresiva en Python
Asi funciona internamente la generacion token por token:
import torch, torch.nn.functional as F
def generate(model, tokenizer, prompt, max_tokens=50, temperature=0.7):
"""Generacion autoregresiva — el loop central de todo LLM."""
input_ids = tokenizer.encode(prompt, return_tensors="pt")
for _ in range(max_tokens):
with torch.no_grad():
logits = model(input_ids).logits[:, -1, :] # prediccion del siguiente token
probs = F.softmax(logits / temperature, dim=-1) # logits -> probabilidades
next_token = torch.multinomial(probs, num_samples=1) # samplear de la distribucion
input_ids = torch.cat([input_ids, next_token], dim=-1) # agregar al contexto
if next_token.item() == tokenizer.eos_token_id:
break # fin de secuencia
return tokenizer.decode(input_ids[0])Como correr LLMs
APIs comerciales
| OpenAI | GPT-4o, GPT-4.1 |
| Anthropic | Claude Sonnet, Opus |
| Gemini 2.5 Pro/Flash | |
| OpenRouter | 100+ modelos, un API |
GPU servers (NVIDIA)
| vLLM | Produccion, batching, PagedAttention |
| TGI | HuggingFace, optimizado |
| TensorRT-LLM | NVIDIA, maxima velocidad |
CPU / local
| llama.cpp | GGUF, CPU/GPU, cualquier OS |
| Ollama | CLI simple, pull & run |
| LM Studio | GUI, descarga modelos, local |
Apple Silicon (ARM)
| MLX / mlx-lm | Apple, Metal nativo |
| vLLM-MLX | vLLM + MLX, 400+ tok/s |
Todos exponen OpenAI-compatible API → cualquiera puede ser el backend de un agente MCP
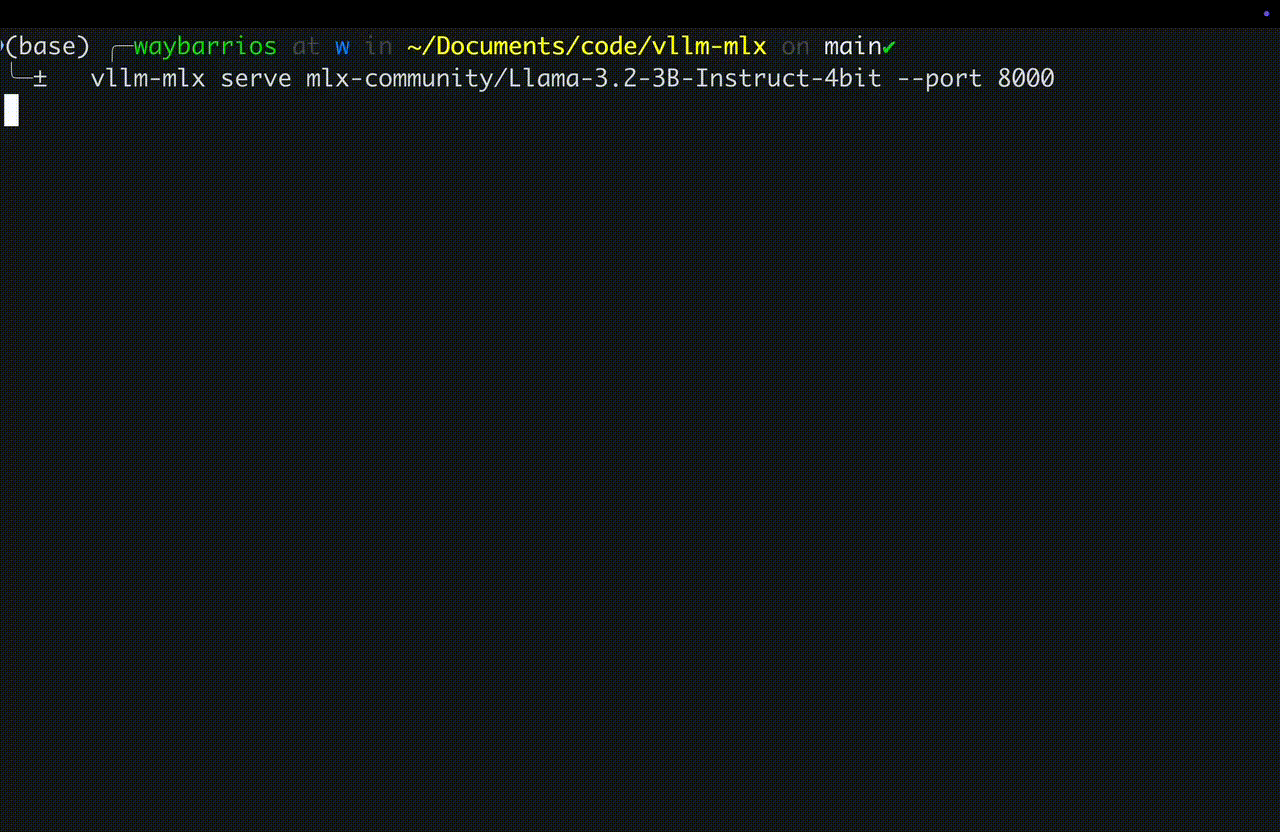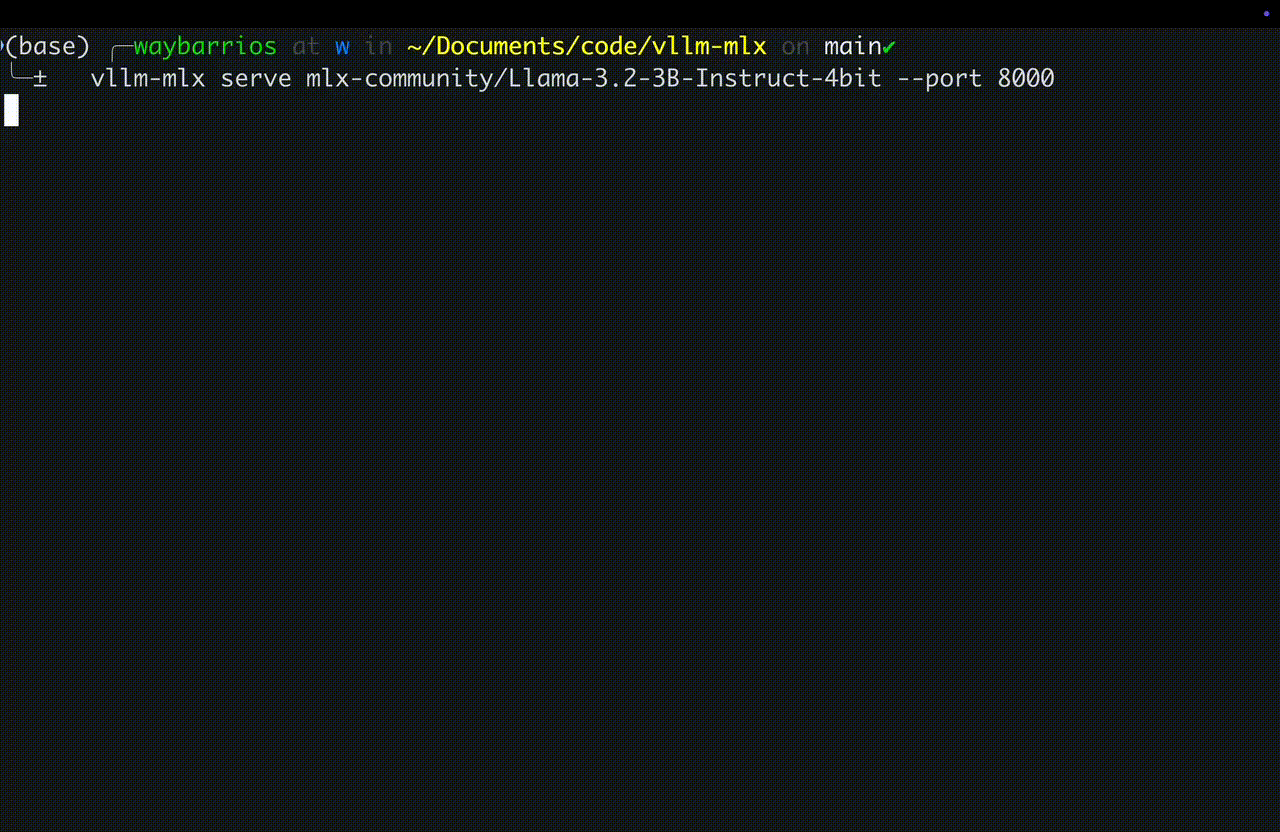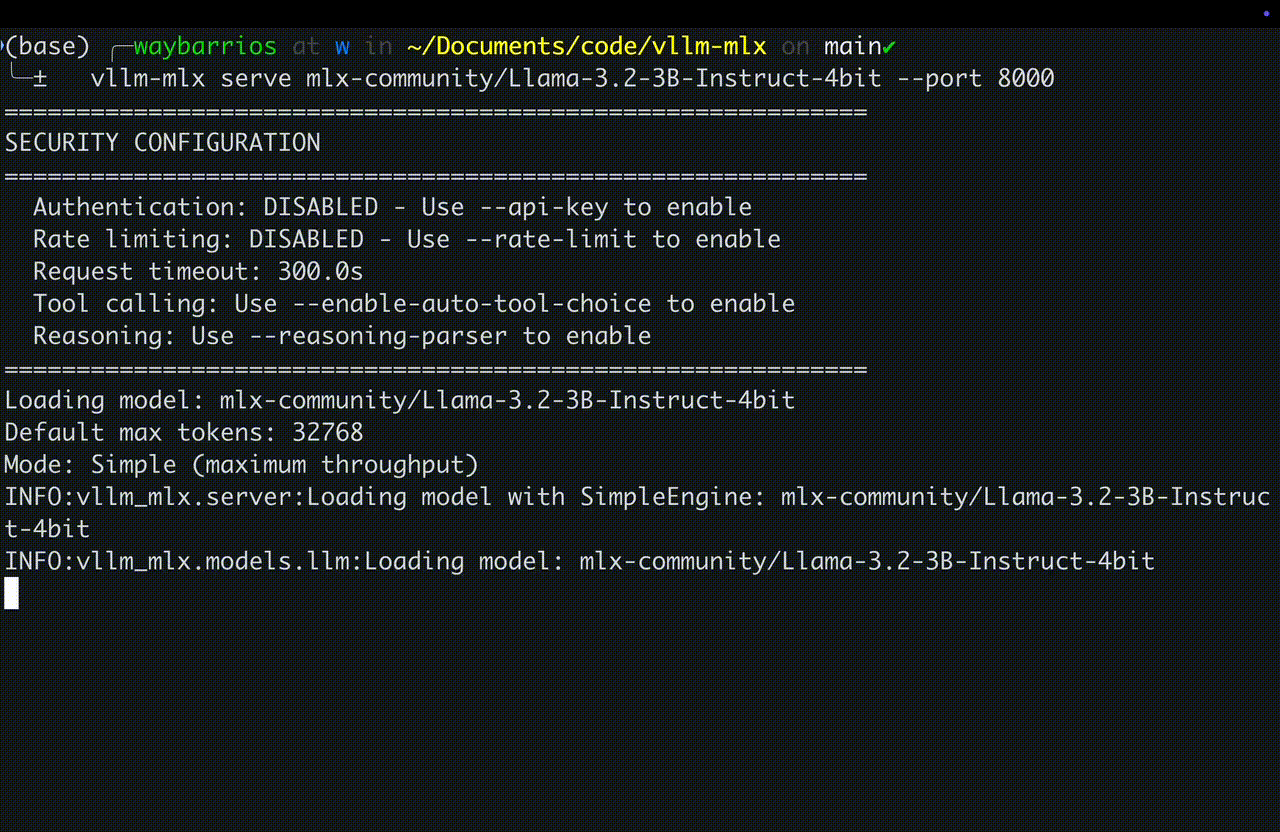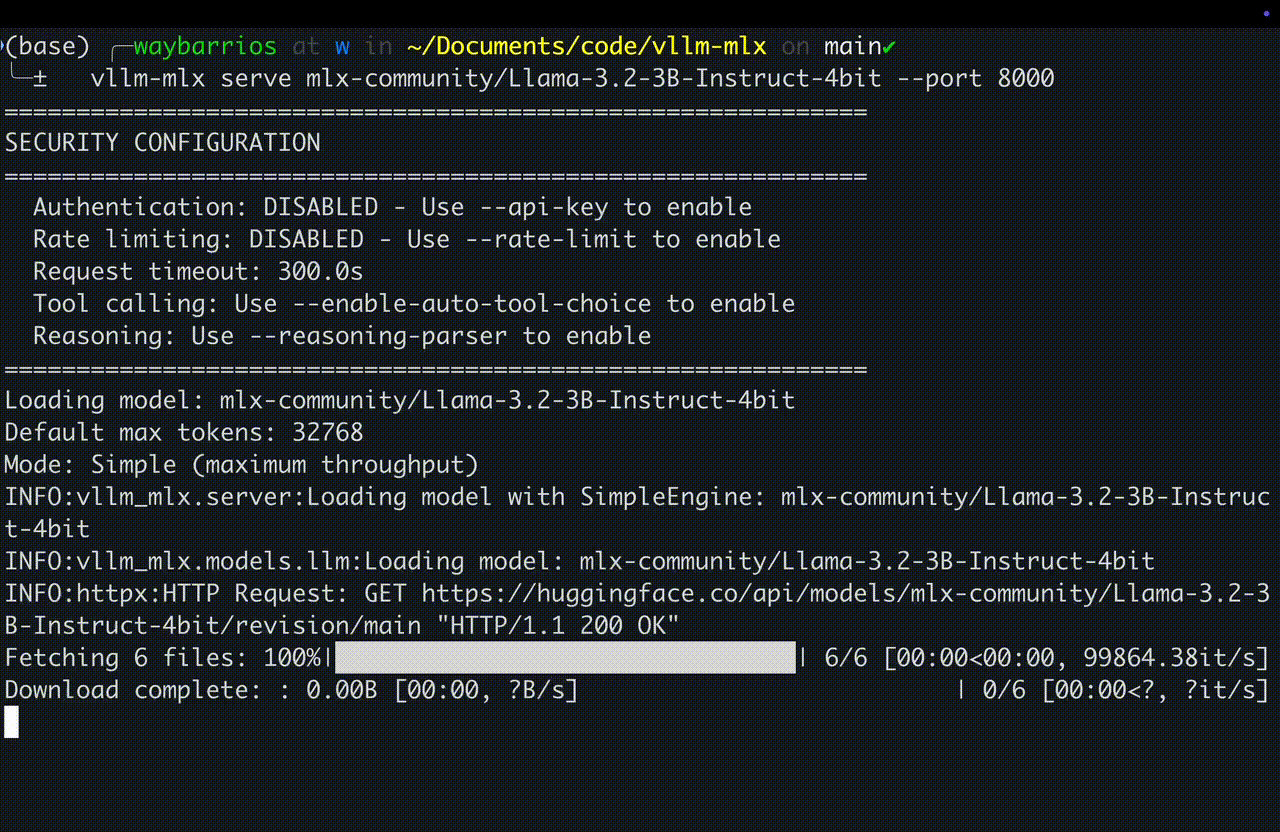
Un LLM server en la practica
vLLM-MLX — servidor OpenAI-compatible en Apple Silicon
# Levantar el servidor (un comando)
vllm-mlx serve \
mlx-community/Llama-3.2-3B-Instruct-4bit \
--port 8000# Usar con OpenAI SDK
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed")
r = client.chat.completions.create(
model="default",
messages=[{"role": "user",
"content": "Que es TCP?"}])
print(r.choices[0].message.content)Servidor arrancando en M4 Max
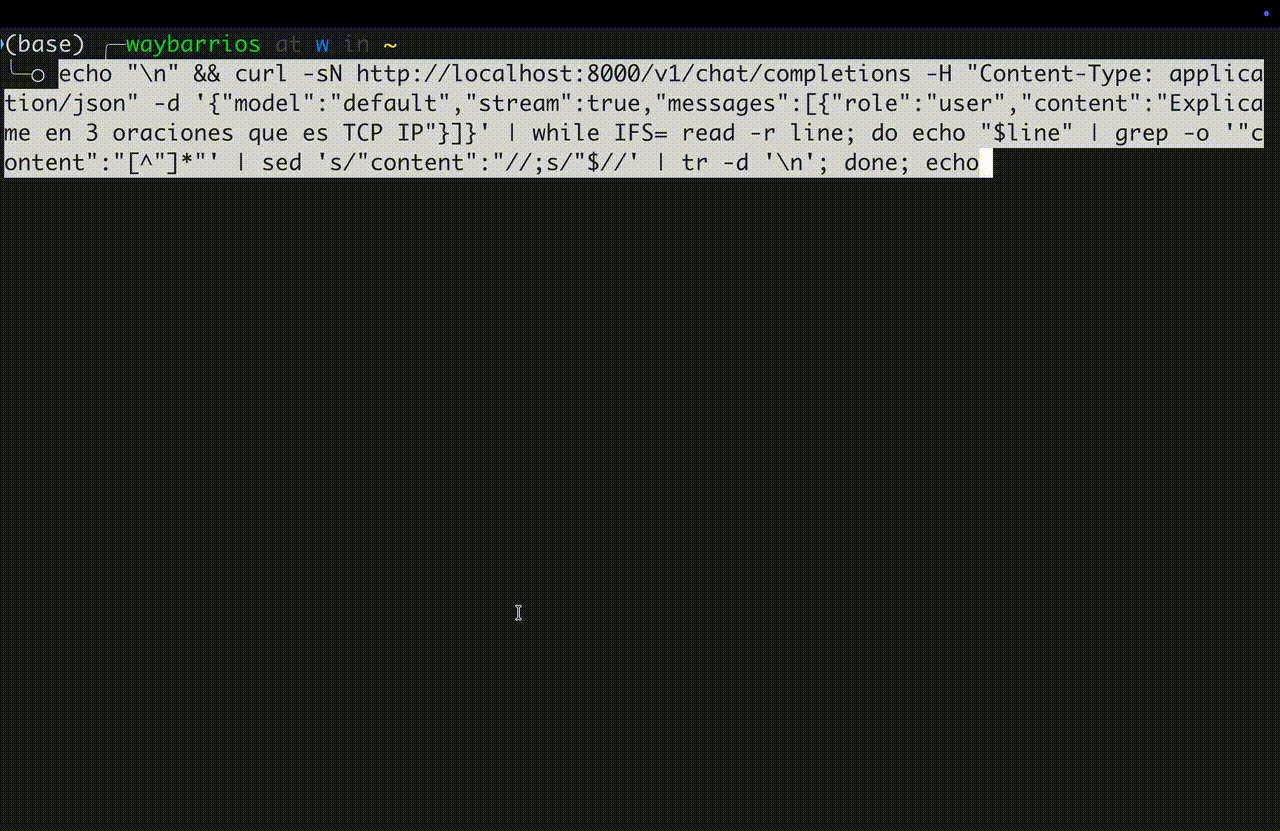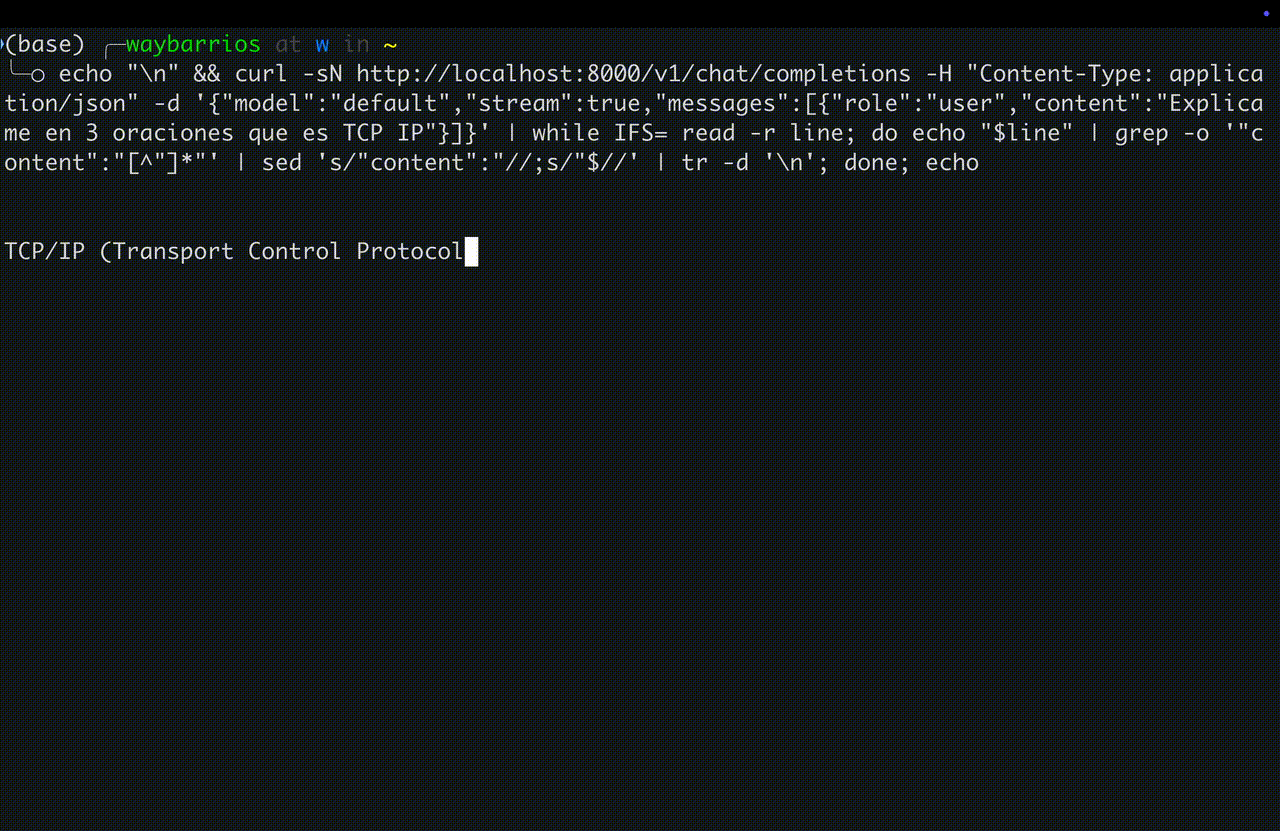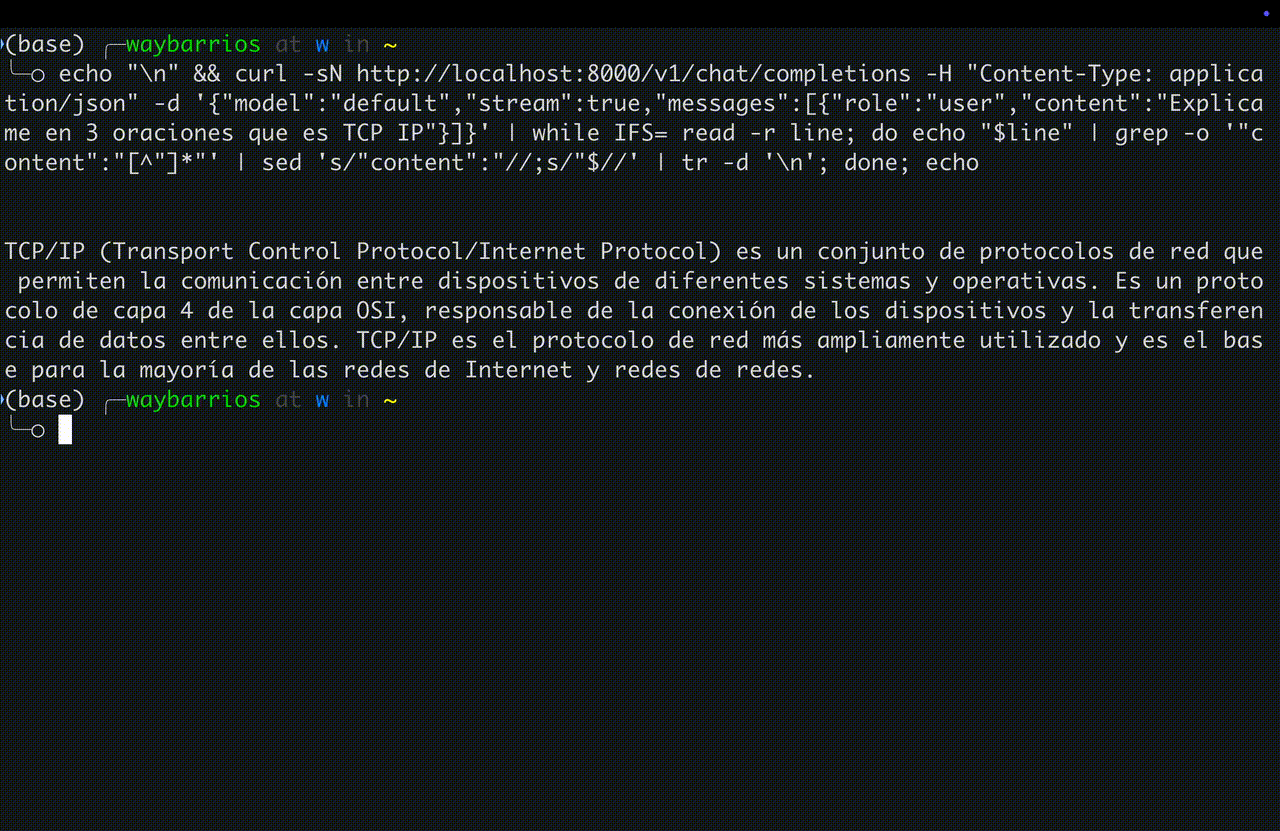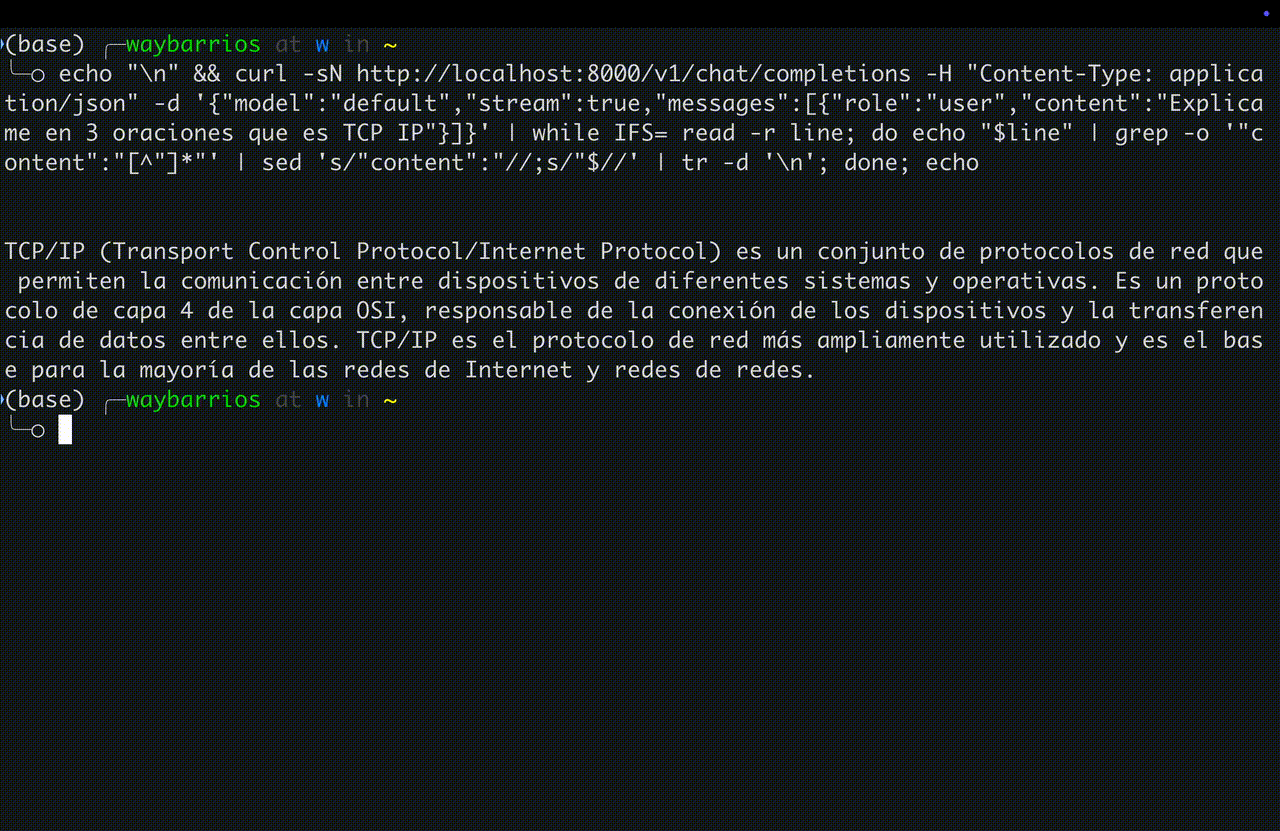
Streaming response — token por token
El salto: de texto a acciones
Antes, los LLMs solo generaban texto. Ahora pueden invocar funciones externas — esto se llama tool use o function calling.
Antes: "La IP del servidor es probablemente 192.168.1.1"
Ahora: El modelo llama ping("192.168.1.1") y te da la respuesta real.
El modelo no ejecuta codigo directamente — genera una llamada estructurada que un runtime ejecuta y le devuelve el resultado.

Function calling — Martin Fowler
Function calling en codigo
Request — define tool y envia prompt:
from huggingface_hub import InferenceClient
client = InferenceClient(model_url)
tools = [{"type": "function",
"function": {
"name": "get_weather",
"description": "Get forecast",
"parameters": {"type": "object",
"properties": {
"location": {"type": "string"},
"days": {"type": "integer"}
}}}}]
response = client.chat_completion(
messages=[{"role": "user",
"content": "Clima en Bogota 3 dias"}],
tools=tools, tool_choice="auto")Response — el modelo elige la funcion:
>>> response.choices[0].message.tool_calls
[{
"function": {
"name": "get_weather",
"arguments": {
"location": "Bogota",
"days": 3
}
}
}]
>>> # No respondio texto!
>>> # Genero una llamada estructurada.
>>> # El runtime ejecuta get_weather()
>>> # y devuelve el resultado al modelo.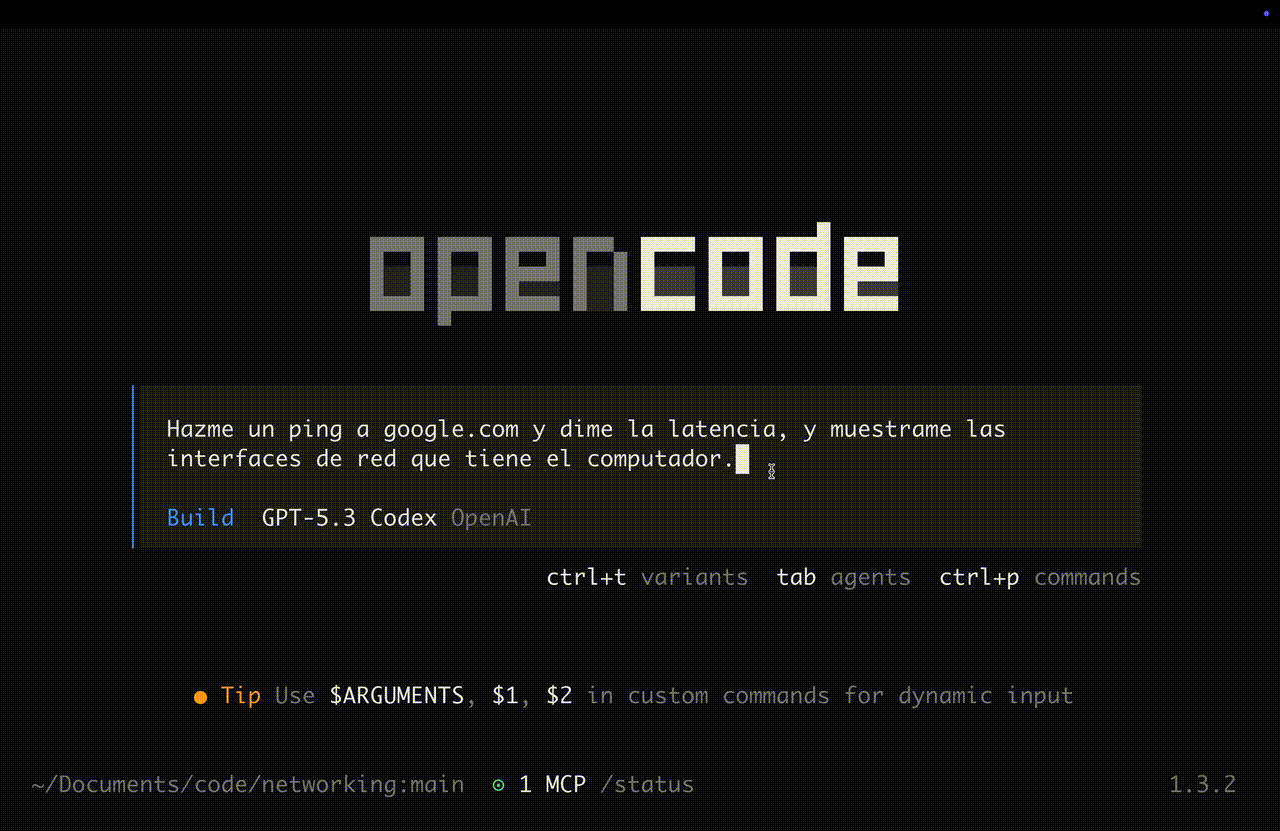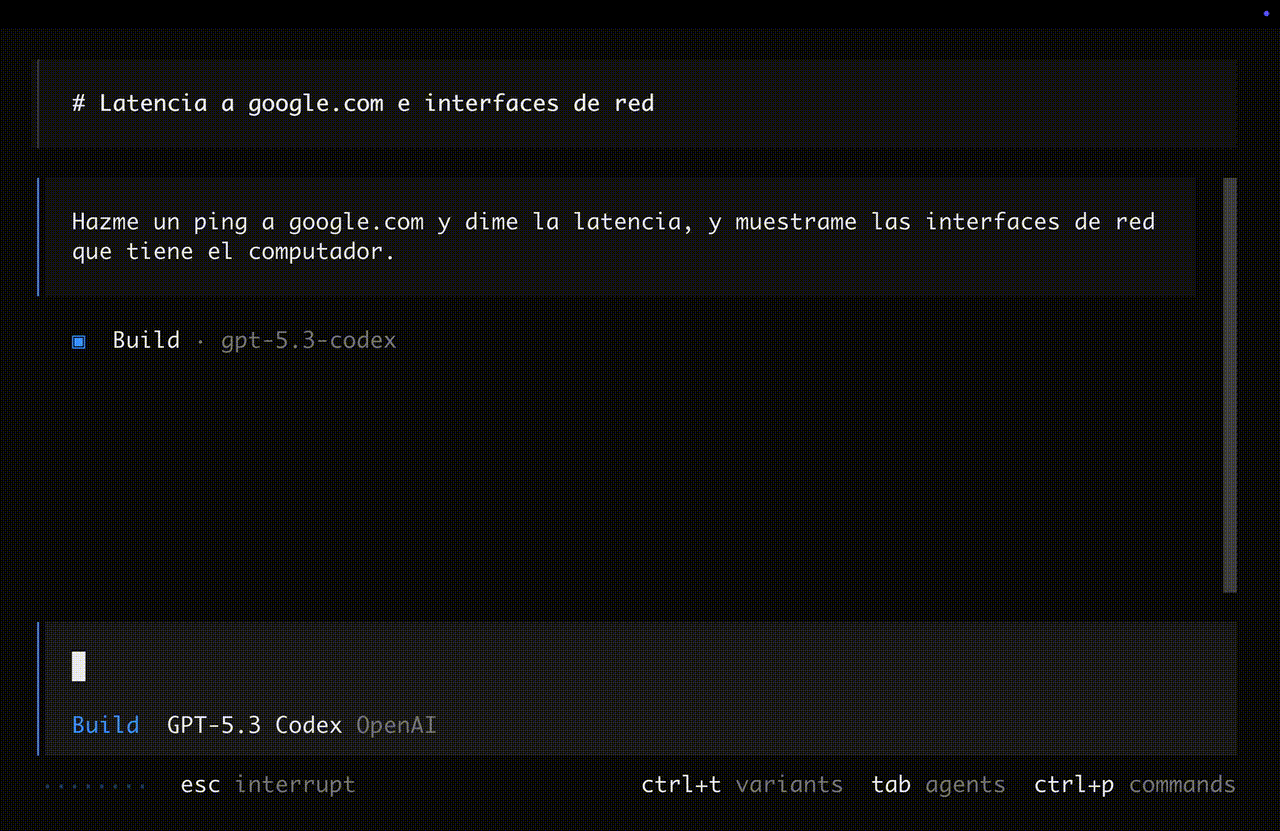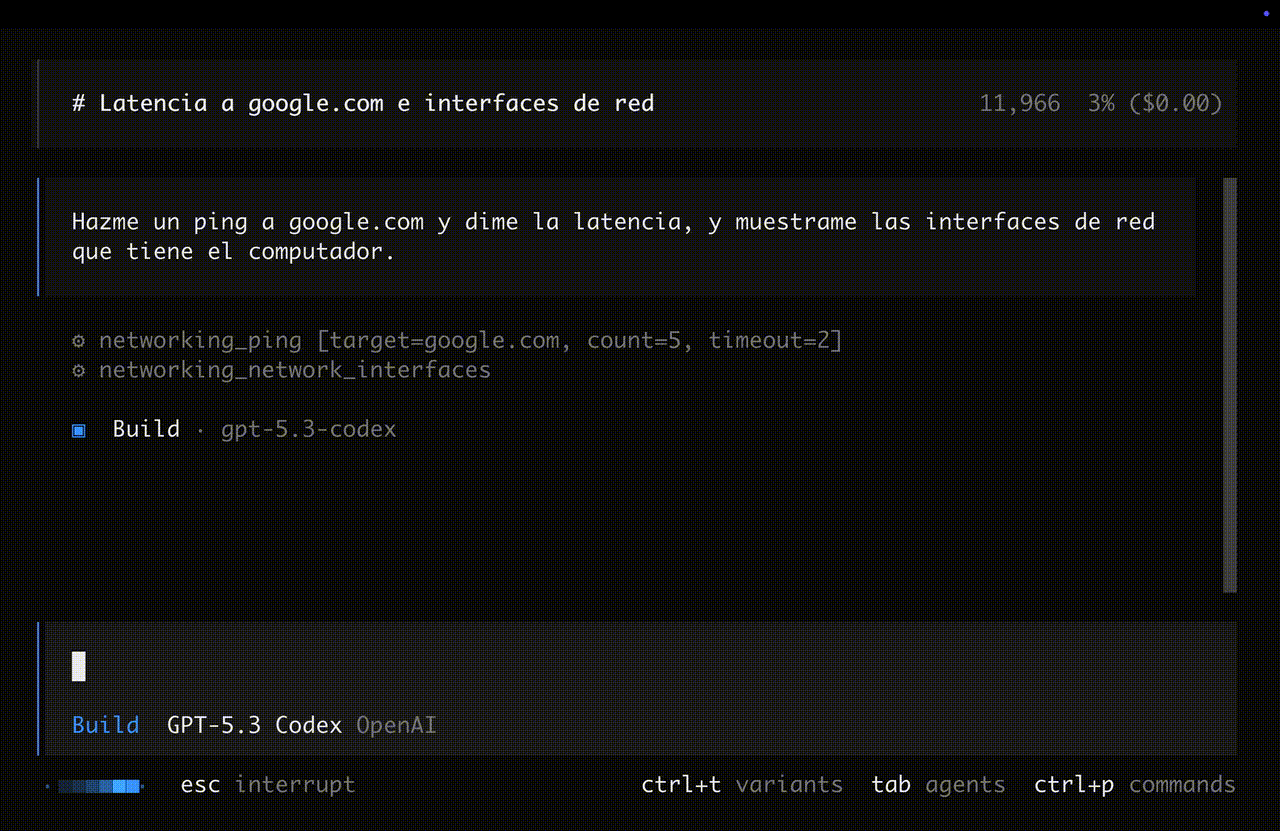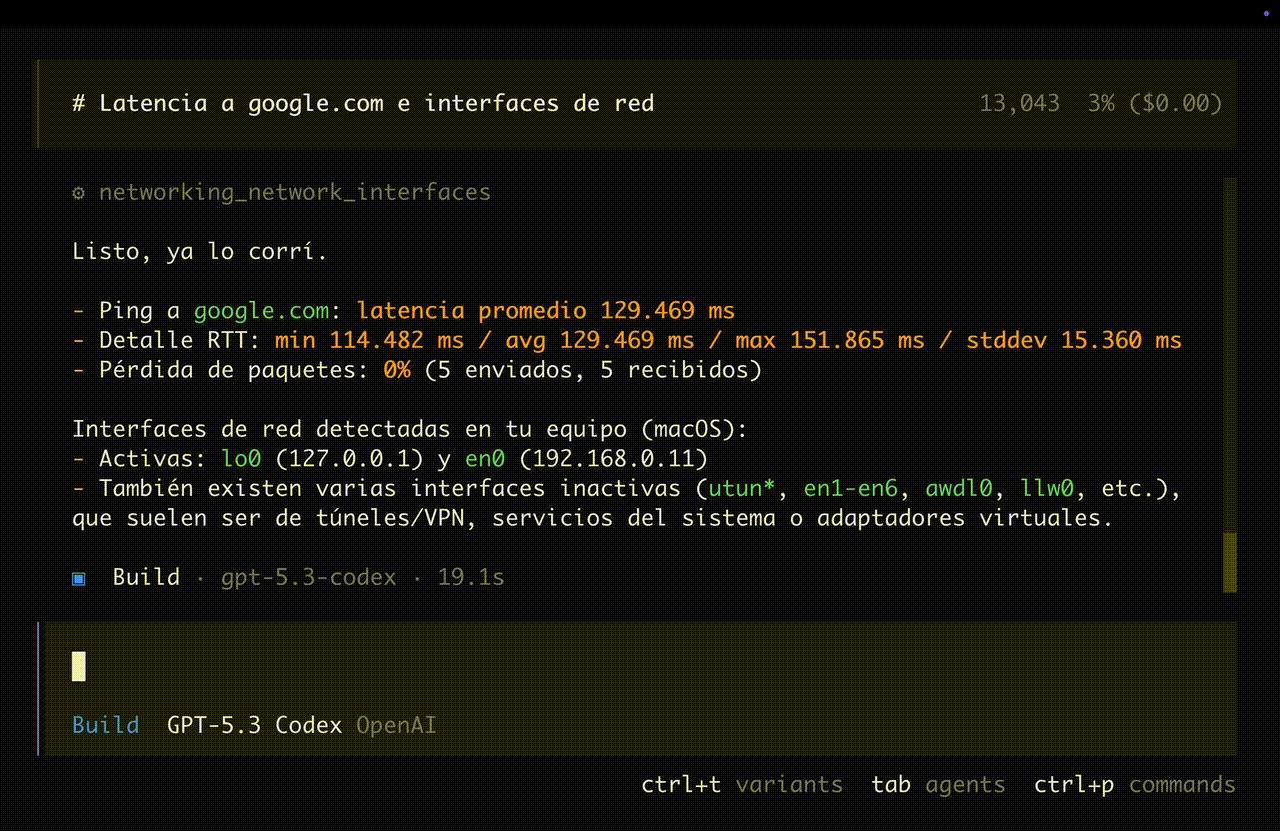
El problema que resuelve MCP
Sin MCP
Cada proveedor de IA tiene su propio formato para tools. Si cambias de modelo, reescribes las integraciones.
Con MCP
Un servidor, un protocolo estandar. Cualquier agente compatible puede usar tus tools. Escribes una vez.
Arquitectura MCP
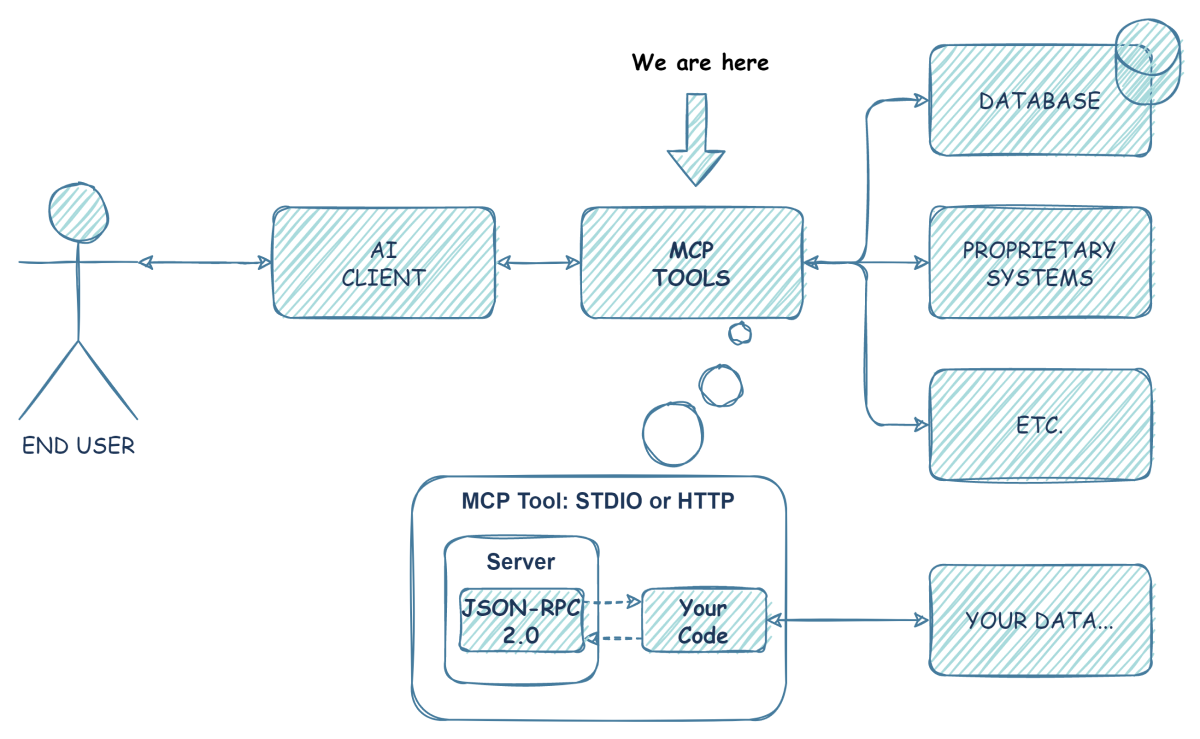
MCP High-Level Architecture — icodealot.com
Host (Claude Code, IDE) contiene el Client que habla JSON-RPC con el Server. El server expone tools, resources y prompts. El agente lee la lista y decide que usar.
JSON-RPC: el protocolo de transporte
RPC (Remote Procedure Call) permite ejecutar una funcion en otro proceso como si fuera local. JSON-RPC 2.0 usa JSON como formato — ligero, sin estado, sobre stdio o HTTP.
// Request: el agente llama una tool
{
"jsonrpc": "2.0",
"method": "tools/call",
"params": {
"name": "scan_network",
"arguments": {"network": "192.168.1.0/24"}
}
}// Response: resultado
{
"jsonrpc": "2.0",
"result": {
"content": [{
"type": "text",
"text": "Hosts descubiertos: ..."
}]
}
}Capa OSI 7 (Aplicacion). MCP transporta JSON-RPC sobre stdio (local) o HTTP+SSE (remoto).
FastMCP: asi de simple
282 lineas. 26 tools. El docstring ES la interfaz que el agente lee.
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("networking")
@mcp.tool()
def tcp_port_scan(target: str, ports: str = "common",
timeout: int = 2) -> str:
"""Escanea puertos TCP de un host usando SYN scan.
Args:
target: IP o hostname del objetivo
ports: "common", rango "1-1024", o lista "80,443"
"""
return port_scan(target, ports, timeout)
# ... 25 tools mas con el mismo patron ...
if __name__ == "__main__":
mcp.run()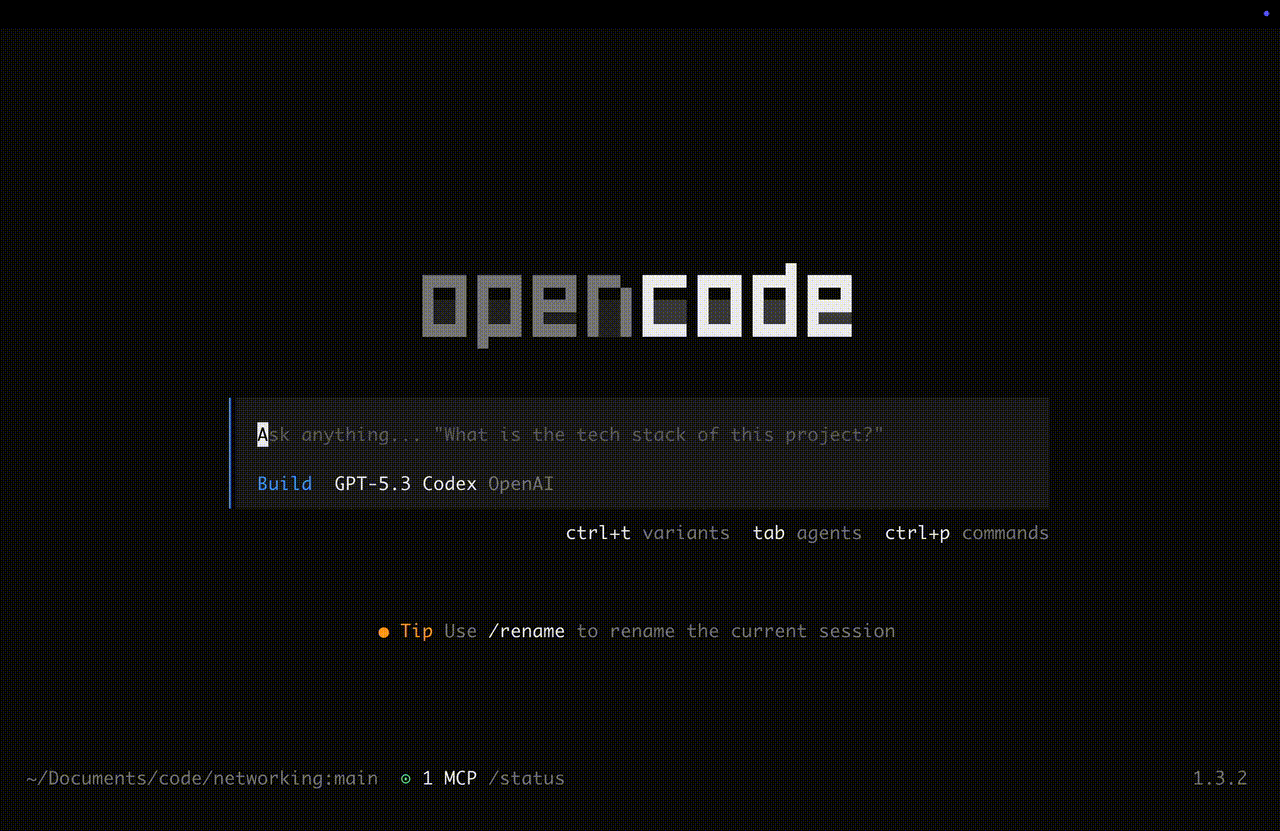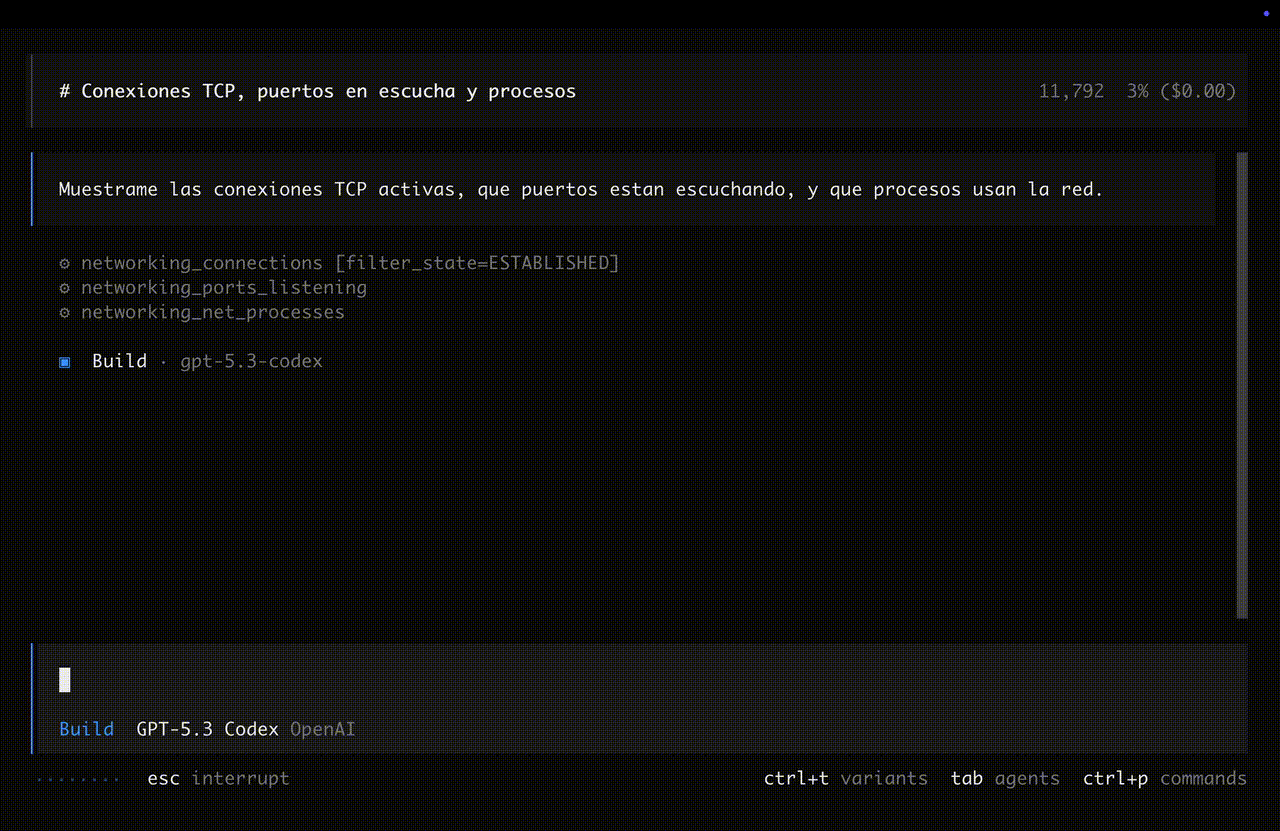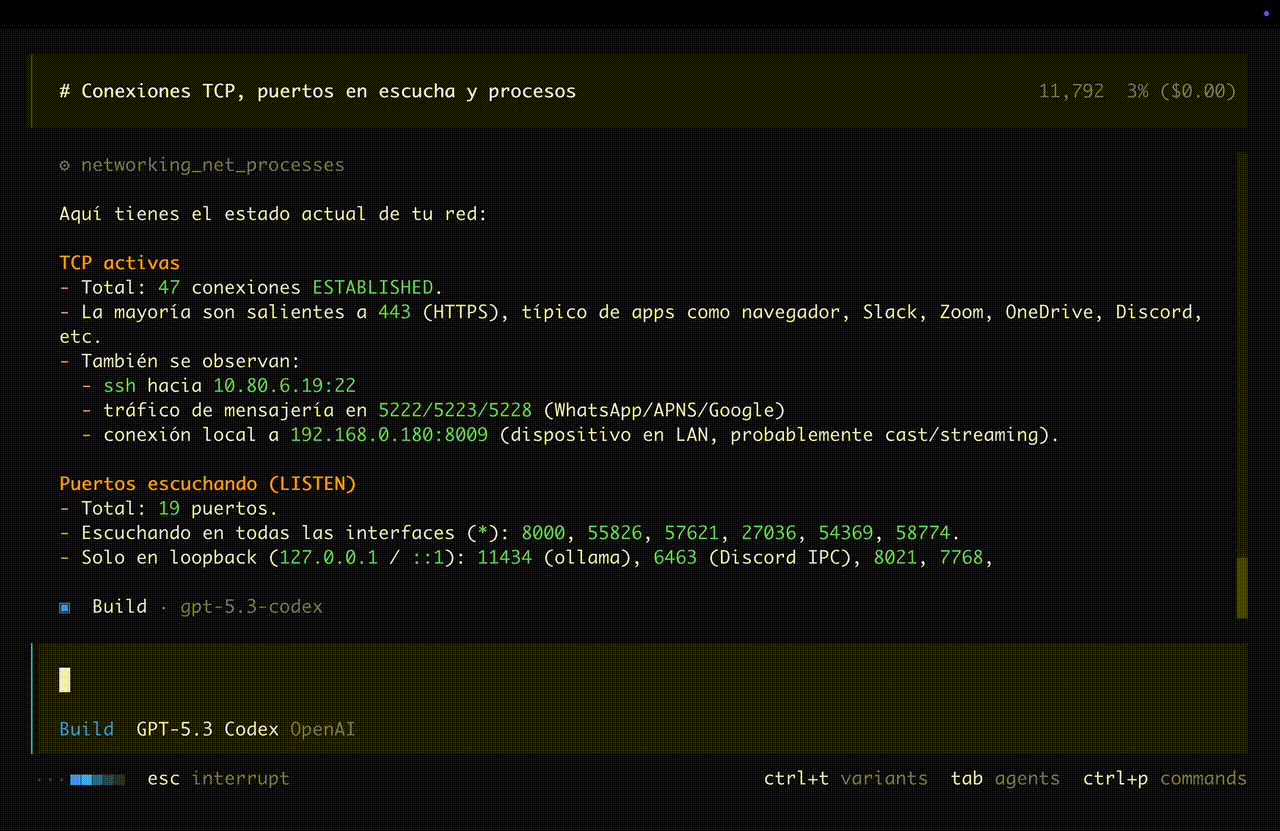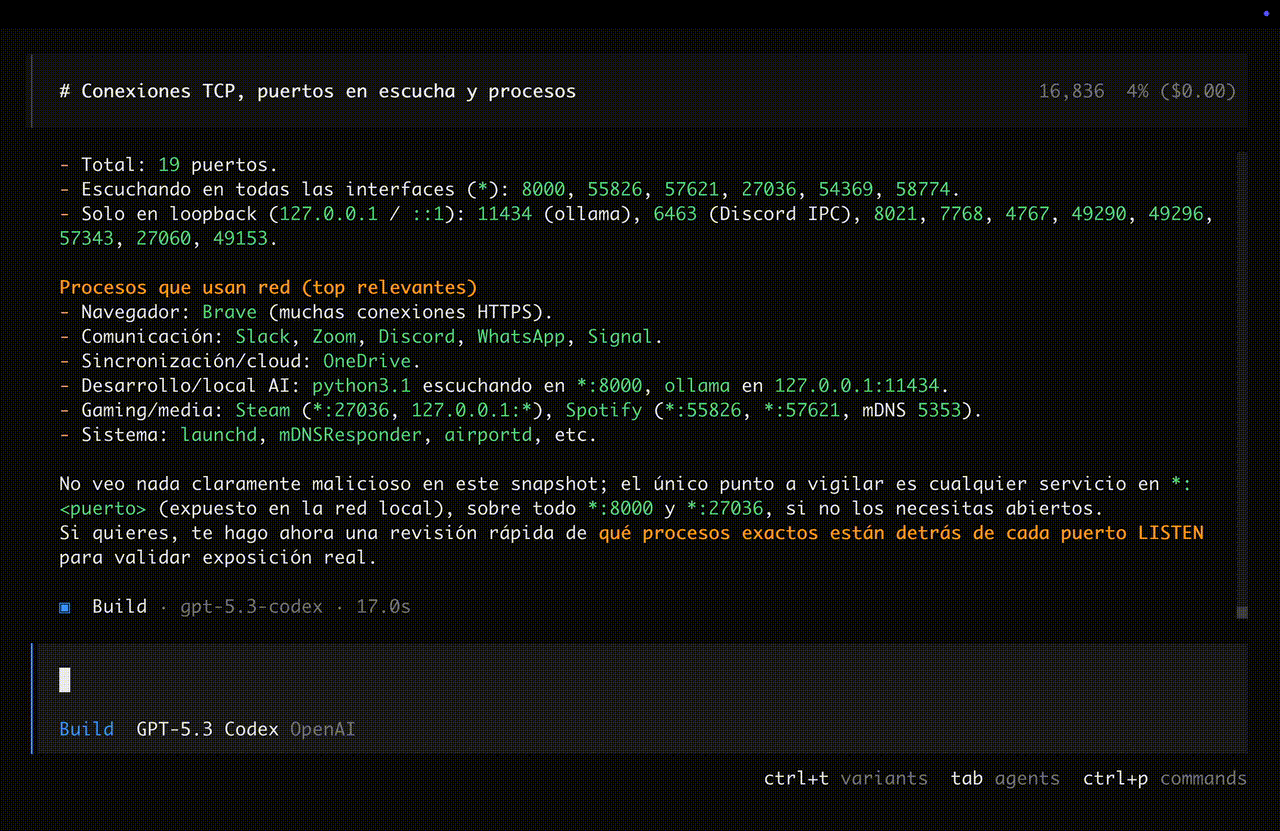
Lo que construimos
Capas de la arquitectura
subprocess → comandos del OS
Scapy → raw sockets
Principio de minimo privilegio: el agente empieza con tools pasivas y solo escala a activas cuando necesita mas informacion.
Que es Scapy
Scapy es una libreria Python que permite construir, enviar, capturar y diseccionar paquetes de red a nivel raw.
- Acceso directo a raw sockets (/dev/bpf en macOS)
- Construye paquetes capa por capa
- Envia y recibe con sr(), srp(), sniff()
- Disecciona respuestas automaticamente
Cada capa se apila con el operador / — Ether() / IP() / TCP()

Modelo OSI — las capas que Scapy manipula
ARP Discovery L2

Protocolo ARP — Request / Reply
ARP (Address Resolution Protocol) resuelve IPs a direcciones MAC en una red local.
- Broadcast: "Quien tiene 192.168.1.X?"
- Cada host activo responde con su MAC
- Enviamos a todo el CIDR de una vez
- Solo funciona en la LAN (Layer 2)
ARP Discovery: el codigo
from scapy.all import ARP, Ether, srp
def arp_scan(network: str, timeout: int = 3) -> str:
# Construir paquete: Ethernet broadcast + ARP request
broadcast = Ether(dst="ff:ff:ff:ff:ff:ff")
packet = broadcast / ARP(pdst=network) # ej: "192.168.1.0/24"
# Enviar y recibir respuestas
answered, _ = srp(packet, timeout=timeout, verbose=0)
hosts = []
for sent, received in answered:
ip = received.psrc # IP del host que respondio
mac = received.hwsrc # MAC address
vendor = _mac_vendor_hint(mac) # OUI lookup
hosts.append((ip, mac, vendor))
# Ordenar por IP y formatear salida
hosts.sort(key=lambda x: list(map(int, x[0].split("."))))dst=ff:ff:ff:ff:ff:ff
pdst=192.168.1.0/24
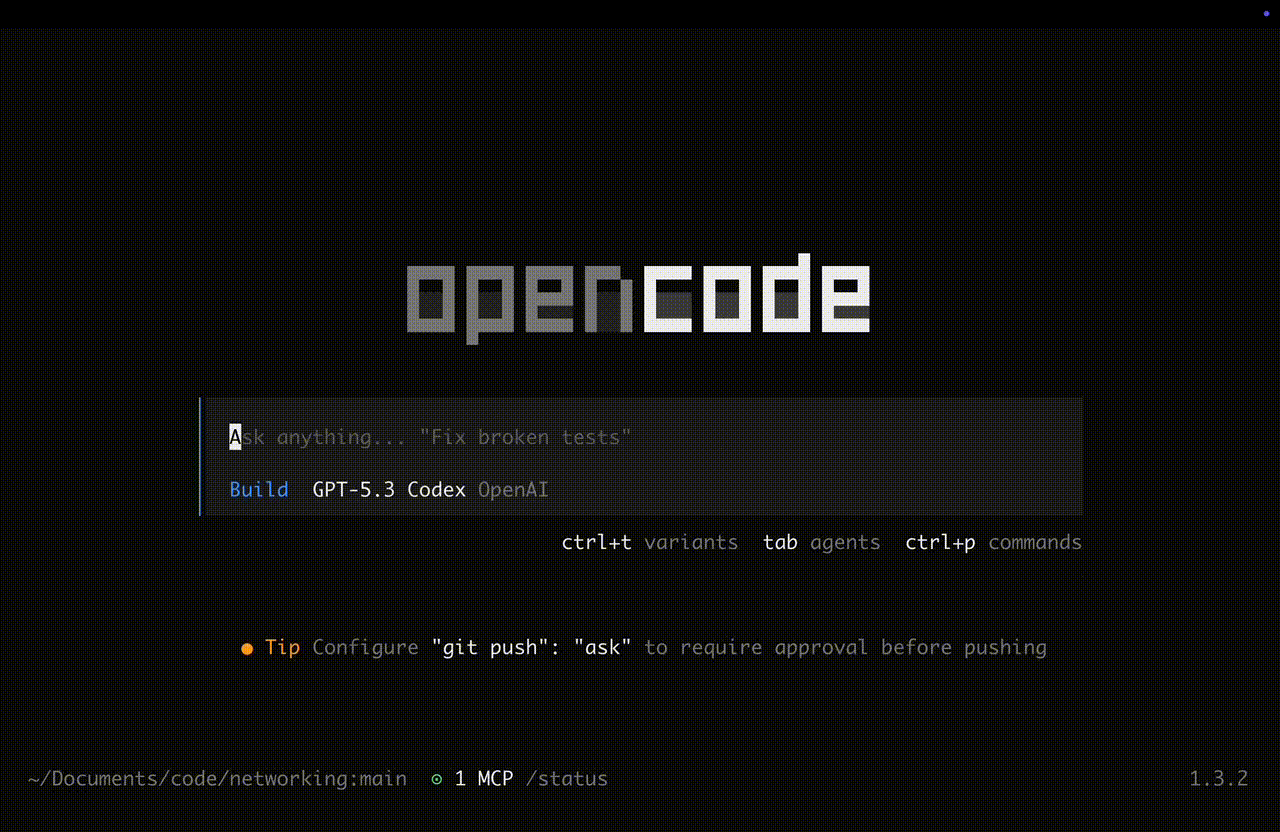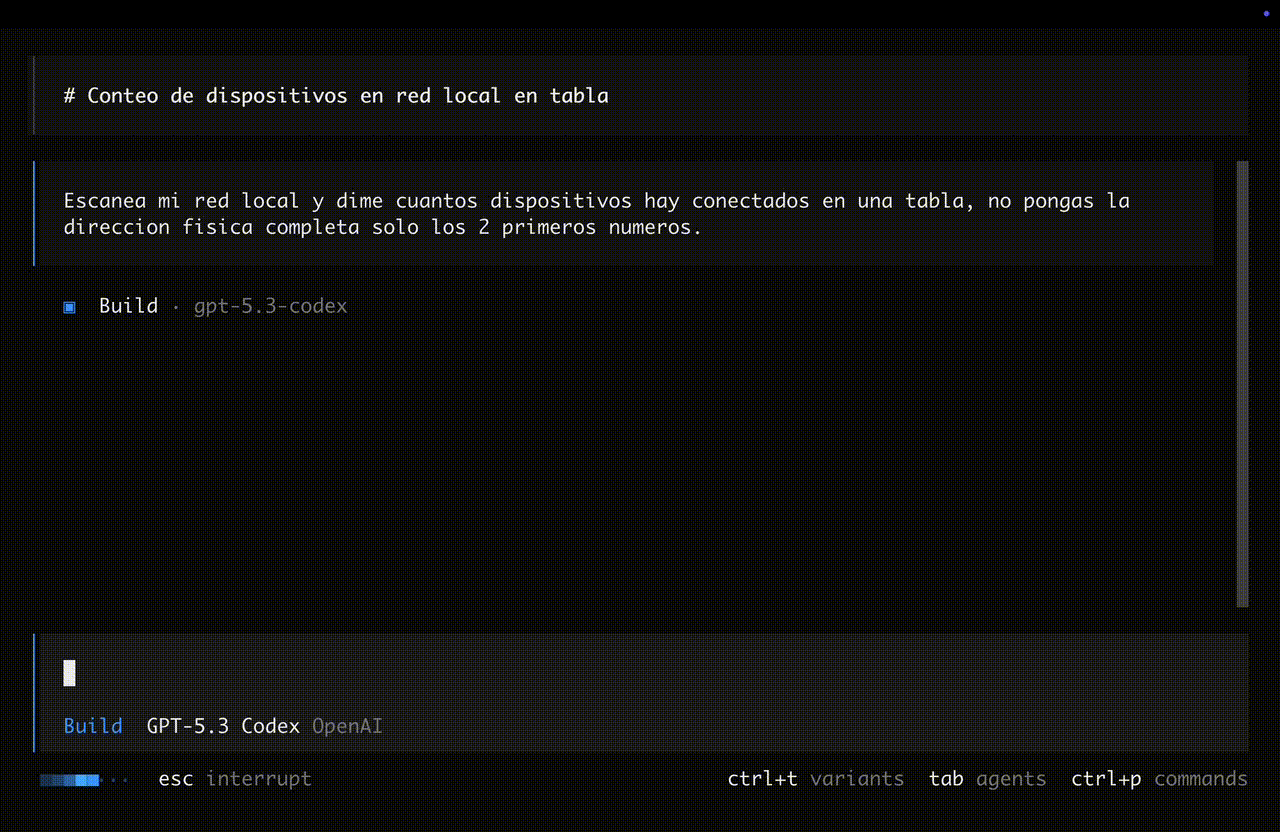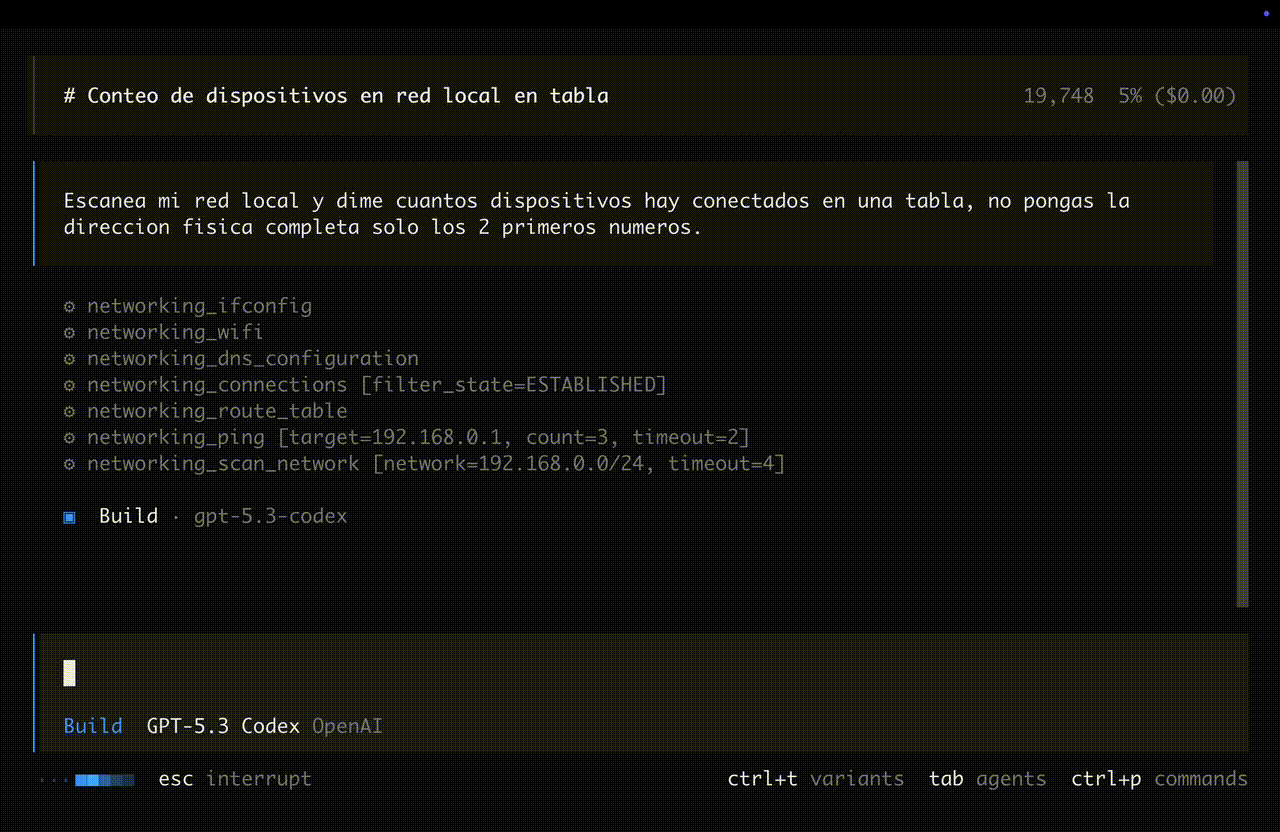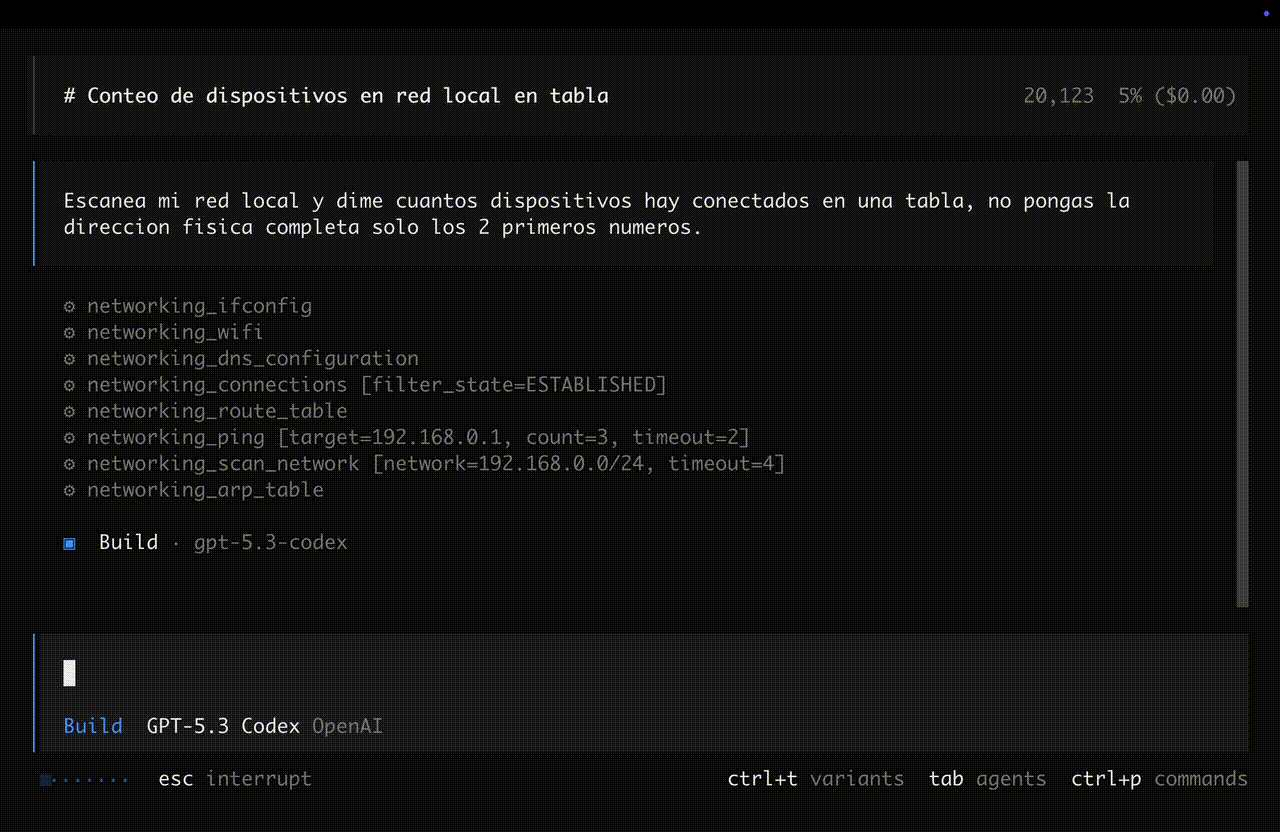
Un solo paquete broadcast descubre todos los hosts activos en la subred
TCP SYN Scan 75+ puertos
El SYN scan (half-open scan) envia un SYN y analiza la respuesta sin completar la conexion.
- SYN-ACK (0x12) = puerto abierto
- RST-ACK (0x14) = puerto cerrado
- Sin respuesta = filtrado
- Enviamos RST para limpiar (nunca connect())
Clave: sr() envia todos los SYN en paralelo. 75 puertos en ~2 segundos.

TCP 3-way handshake — el SYN scan interrumpe en paso 2
SYN Scan: el codigo
# Enviar TODOS los SYN de golpe (paralelo, no secuencial)
pkts = IP(dst=target) / TCP(dport=port_list, flags="S")
answered, unanswered = sr(pkts, timeout=2, verbose=0)
for sent, received in answered:
if received[TCP].flags == 0x12: # SYN-ACK = ABIERTO
open_ports.append(sent[TCP].dport)
elif received[TCP].flags == 0x14: # RST-ACK = cerrado
closed_ports += 1
# Limpieza: cerrar half-open connections
rst = IP(dst=target) / TCP(dport=[p for p, _ in open_ports], flags="R")
sr(rst, timeout=1, verbose=0)Paralelo
sr() envia todos los SYN simultaneamente.
Half-open
Nunca completa el handshake. Envia RST para limpiar.
75+ puertos
HTTP, SSH, MySQL, Docker, K8s, Redis, y mas.
Sniffing y Traceroute
Packet Sniffing — BPF filters:
pkts = sniff(count=20,
filter="tcp port 80", timeout=30)
for pkt in pkts:
if pkt.haslayer(TCP):
flags = str(pkt[TCP].flags)
if pkt.haslayer(DNS):
query = pkt[DNS].qd.qname.decode()Traceroute — 3 metodos + abort inteligente:
for ttl in range(1, max_hops + 1):
if method == "tcp":
pkt = IP(dst=target, ttl=ttl) \
/ TCP(dport=80, flags="S")
else:
pkt = IP(dst=target, ttl=ttl) / ICMP()
resp = sr1(pkt, timeout=1, verbose=0)
if resp is None:
timeouts += 1
if timeouts >= 10: break # abortZero lineas de workflow
Enfoque tradicional
def diagnostico():
r1 = ping("8.8.8.8")
r2 = ifconfig()
cidr = extraer_cidr(r2)
r3 = scan_network(cidr)
for host in r3:
port_scan(host)
# ... 200 lineas mas
# fragil, rigido, hardcodedNuestro enfoque
@mcp.tool()
def ping(): """Mide latencia..."""
@mcp.tool()
def scan_network(): """Descubre hosts..."""
@mcp.tool()
def tcp_port_scan(): """Escanea puertos..."""
# 26 tools. Zero orchestration.
# El agente lee los docstrings
# y decide el flujo solo.El secreto: el docstring es la orquestacion
Lo que escribimos:
@mcp.tool()
def scan_network(network: str, timeout: int = 3) -> str:
"""Descubre hosts activos en la red
usando ARP scan.
Args:
network: Rango CIDR a escanear
(ej: "192.168.1.0/24")
timeout: Tiempo de espera (default: 3)
"""
@mcp.tool()
def tcp_port_scan(target: str,
ports: str = "common") -> str:
"""Escanea puertos TCP de un host
usando SYN scan.
Args:
target: IP o hostname del objetivo
ports: "common" o rango "1-1024"
"""Lo que el agente razona:
"scan_network necesita un CIDR... no lo tengo. Voy a llamar ifconfig primero para obtener mi IP y calcular el rango."
"scan_network me devolvio 7 hosts. tcp_port_scan necesita un target... el .200 no parece comun. Lo escaneo."
"Puerto 3306 abierto... eso es MySQL. Deberia verificar si hay trafico activo hacia ese puerto."
Cada output es el input del siguiente paso
Nadie programo esta cadena. El agente la descubrio leyendo docstrings.
Recapitulando
- FastMCP + Scapy + raw sockets = analisis completo de red
- 13 pasivas (sin root) + 13 activas (Scapy) = minimo privilegio
- Multiplataforma: macOS, Linux, Windows
- Comportamiento emergente: el agente aprende el workflow solo
- Cada resultado informa la siguiente decision